文檔自動轉換方案| ABBYY識別服務器

ABBYY識別服務器為文檔的自動擷取和PDF轉換,提供強大OCR功能的服務器。為分批處理大量文件而設計,讓公司和掃描服務商通過將紙質文件如TIFF、JEPG和PDF圖片文件,轉換成可全文搜索並長期數碼存檔的電子文檔的格式,建立合算的工作流程。
選擇ABBYY Recognition Server的理由

自動轉換為PDF和PDF/A格式
能使大型文件包數碼化並將掃描文件自動轉換為PDF或PDF/A格式,以便電子化存儲及歸檔。

企業級文檔轉換服務
為員工和客戶提供一個能隨時隨地在線的靈活OCR和文件轉換服務器。

創建可全文本搜索的數據庫
將掃描件或者傳真件轉換為可搜索文本並存儲在Microsoft® SharePoint®數據庫,以便通過SharePoint搜索引擎進行搜索。
OCR 的授權
產品優點
用於數字化存檔、電子搜索和企業內部訪問的自動化文檔轉換方案
Recognition Server自動從掃描件、文件、傳真件、郵件和Microsoft SharePoint數據庫中獲取圖片,執行服務器端的光學字符識別(OCR)並允許添加元數據。將這些結果以需要的格式直接傳送到網絡文件夾,SharePoint數據庫或者其它存儲、管理系統。這些格式包括MRC壓縮的可搜索PDF或PDF / A文件,XML數據,可編輯文檔(如Microsoft Word和Excel®文件)和純文本文件。
識別服務器的分佈式和高度可擴展的架構意,味著它可以在網絡中的多個服務器上運行,並在短時間內轉換大量文檔。其快速部署,易於管理和自動化工作程序,使識別服務器成為帶來快速回報的投資。
強大的基於服務器的OCR軟件,用於自動文檔擷取和PDF轉換。
產品亮點
自動轉換為PDF & PDF/A格式
• 創建全文本可搜索的SharePoint數據庫
• 企業級文檔轉換服務器
自動將文檔數字化
如何工作?
1.靈活導入選擇
從網絡/FTP文件夾導入
ABBYY識別服務器能夠從以下網絡資源自動導入圖片:
- 網絡文件夾
- FTP文件夾(例如,從遠程位置上傳的圖片)
- 電子郵件文件夾(例如,用戶用電子郵件為客戶傳的送圖片)
文件輸入格式
- TIFF/多頁TIFF
壓縮方式:打開,CCITT Group 3, CCITT Group 3 FAX(2D), CCITT Group4, PackBits, JPEG, ZIP, LZW - JPEG, JPEG 2000
- DjVu
- BMP
- PNG
- PCX, DCX
2. 掃描工作站
掃描工作站提供了批量掃描功能,並做好進一步處理圖片的準備:
- 通過TWAIN, WIA and ISIS掃描.
- 快速預覽圖片
- 圖像預處理(旋轉、抗扭曲、去處雜點等)
- • 文檔條形碼、空白頁、頁碼分離。
對於批量掃描的圖像,ABBYY Recognition Server提供幾個內置文件分離功能:在每個文檔的第一頁上粘貼或打印的空白頁,條形碼紙或條形碼。基於識別的文本的其他自定義規則,可以使用腳本創建。
為了保留原始文檔佈局,ABBYY Recognition Server使用自適應文檔識別技術(ADRT)。將文檔保存為DOC和RTF格式時,ADRT可顯著提高文檔佈局保留。複製整個文檔的邏輯結構,包括頁眉,頁腳,腳註,頁碼,鏈接到文檔部分的目錄以及圖片和圖表的註釋。
支持眾多識別語言
- 43種主要語言,字典支持: Arabic (Saudi Arabia), Armenian (Eastern), Armenian (Grabar), Armenian (Western), Azeri (Latin), Bashkir, Bulgarian, Catalan, Croatian, Czech, Danish, Dutch, Dutch (Belgian), English, Estonian, Finnish, French, German, German (new spelling), Greek, Hebrew, Hungarian, Indonesian, Italian, Latvian, Lithuanian, Norwegian, Norwegian (Bokmal), Norwegian (Nynorsk), Polish, Portuguese, Portuguese (Brazilian), Romanian, Russian, Slovak, Slovenian, Spanish, Swedish, Tatar, Thai, Turkish, Ukrainian, Vietnamese;
- 沒詞典支持的133種附加語言: Abkhaz, Adyghe, Afrikaans, Agul, Albanian, Altai, Avar, Aymara, Azerbaijani (Cyrillic), Basque, Belarusian, Bemba, Blackfoot, Breton, Bugotu, Buryat, Cebuano, Chamorro, Chechen, Chukchee, Chuvash, Corsican, Crimean Tatar, Crow, Dargwa, Dungan, Eskimo (Cyrillic), Eskimo (Latin), Even, Evenki, Faroese, Fijian, Frisian, Friulian, Gagauz, Galician, Ganda, German (Luxembourg), Guarani, Hani, Hausa, Hawaiian, Icelandic, Indonesian, Ingush, Irish, Jingpo, Kabardian, Kalmyk, Karachay-balkar, Karakalpak, Kasub, Kawa, Kazakh, Khakass, Khanty, Kikuyu, Kirghiz, Kongo, Koryak, Kpelle, Kumyk, Kurdish, Lak, Latin, Lezgi, Luba, Macedonian, Malagasy, Malay (Malaysian), Malinke, Maltese, Mansi, Maori, Mari, Maya, Miao, Minangkabau, Mohawk, Moldavian, Mongol, Mordvin, Nahuatl, Nenets, Nivkh, Nogay, Nyanja, Ojibway, Ossetian, Papiamento, Provencal, Quechua, Rhaeto-Romanic, Romany, Rundi, Russian (Old Spelling), Rwanda, Sami (Lappish) , Samoan, Scottish Gaelic, Selkup, Serbian (Cyrillic), Serbian (Latin), Shona, Sioux (Dakota), Somali, Sorbian, Sotho, Sunda, Swahili, Swazi, Tabasaran, Tagalog, Tahitian, Tajik, Tok Pisin, Tongan, Tswana, Tun, Turkmen, Tuvinian, Udmurt, Uigur (Cyrillic), Uigur (Latin), Uzbek (Cyrillic), Uzbek (Latin), Welsh, Wolof, Xhosa, Yakut, Yiddish, Zapotec, and Zulu;
- 5種東亞語言: 中文(繁體,簡體),日文和韓文;
- 6種語言用於識別18-20世紀印刷的書籍中的舊歐洲文獻和哥特式字體:
- 英語
- 法語
- 德語
- 意大利語
- 西班牙語
- 拉脫維亞語
- 4種人造語言: Esperanto, Ido, Interlingua, and Occidental;
- 6種程式語言:Basic, C/C++, COBOL, Fortran, Java, and Pascal;
- 簡單的化學公式
- 數字
- 一維條碼
- Check Code 39, Check Interleaved 25, Code 128, Code 39, EAN 13, EAN 8, Interleaved 25, CODABAR (without checksum), UCC Code 128, Code 2 of 5 (Industrial, IATA, Matrix), Code 93, UPC-A, UPC-E, Patch Code and Postnet;
- 二維條碼
- PDF 417, Aztec, Data Matrix, QR Code
- 多種文本類型
- Normal, Fax (mode for low-resolution texts), Typewriter, Dot Matrix Printer, OCR-A, OCR-B, MICR (E13B), Gothic
自動質量控制允許管理員為識別準確度設置閾值:文檔質量不佳的文檔不會被轉換,而是存儲在單獨的文件夾中進行特殊處理。
驗證站
用於校對識別結果的客戶端工作站。 可以為所有頁面啟用驗證,也可以根據準確性閾值進行驗證。 支持驗證權限管理。
索引站
用於文檔索引和分類的客戶端工作站。
1. 多目標地數據導出
ABBYY識別服務器為數據和圖像啟用多個目標,並生成可搜索的PDF。
2. 靈活文件輸出格式
- PDF, PDF/A-1a, PDF/A-1b, PDF/-2a, PDF/A-2b, PDF/A-2u
- RTF
- DOC, DOCX
- XLS, XLSX
- TXT, CSV
- HTML
- TIFF
- JPEG, JPEG 2000
- JBIG2
- PNG
- EPUB
- XML, Alto XML
- FineReader 內部格式 (FineReader 引擎兼容)
3. 企業系統的可用連接器
- 導出至Microsoft SharePoint
- IFilter用於TIFF文件
- 連接器至Google Search Appliance
4. 可用的定制和集成選項
- 通過XML文件定義的自定義處理參數(XML票據)
- WEB API
- COM API
- 在VBScript和JScript中編寫手稿
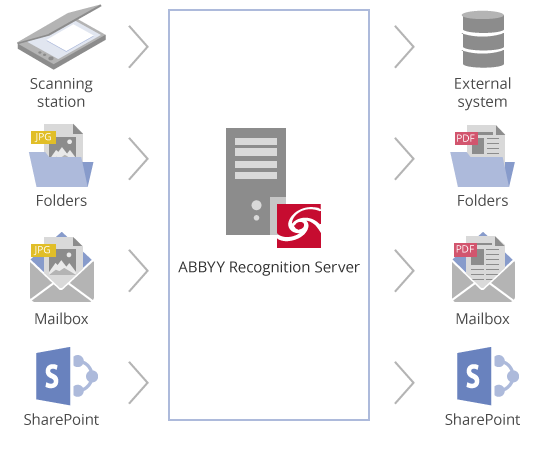
ABBYY Recognition Server可自動將大量紙質文檔或文檔圖像轉換為適合業務流程(包括歸檔,電子發現和企業搜索)的完全可搜索的電子文本。 它使自動化的,無人值守的文件處理 可以從組織內部或遠程管理和訪問。 Recognition Server還可以連接各種後端系統和第三方應用程序,通過腳本,XML票據,Web服務API或基於COM的API進行集成。 ABBYY智能OCR和PDF轉換技術提供高度準確的文檔轉換,最多可識別190種語言。
架構
ABBYY識別服務器由多個組件組成,可安裝在局域網中的一台或多台計算機上。 主要組件是:
- 服務器管理器 – 一個中央服務組件,它控製文檔處理隊列並在工作站之間分配任務。
- 處理站 – 執行識別和文檔轉換的服務。
- 掃描站 – 用於批量掃描和圖像預處理的客戶端工作站。
- 索引站 – 用於文件索引和分類的客戶端站。
- Google Search Appliance™(GSA)連接器 – 允許Google Search Appliance使用ABBYY Recognition Server從文檔圖像中提取內容的組件。
- Microsoft®Search Systems(IFilter)連接器 – 允許Microsoft Office SharePoint Server和Windows Search使用ABBYY Recognition Server從文檔圖像中提取內容的組件。
- 遠程管理控制台 – 用於配置和監視識別服務器的客戶端控制台。
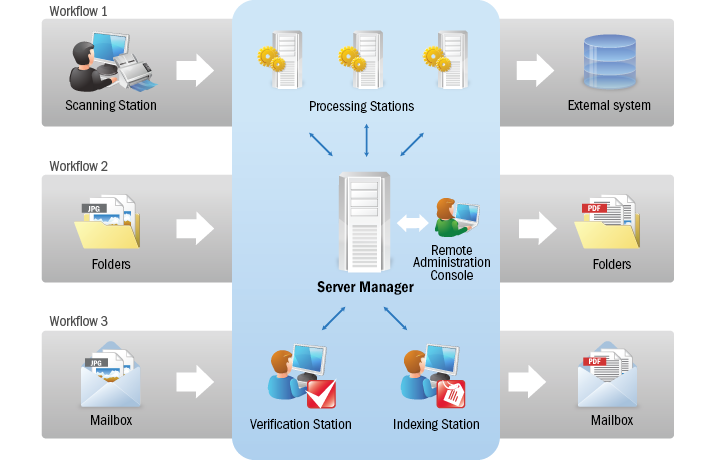
文件處理
ABBYY Recognition Server根據工作流程處理每個圖像文件 – 管理員預定義的一組處理參數。 ABBYY識別服務器可以同時運行具有不同參數的多個工作流程。 每個工作流程都對應一個唯一的輸入源(一個文件夾,一個SharePoint庫或一個郵箱)。
處理步驟
ABBYY Recognition Server中的工作流程通常包含多達六個可配置階段。 根據自己的日程安排和優先級,每個工作流獨立於其他工作流。
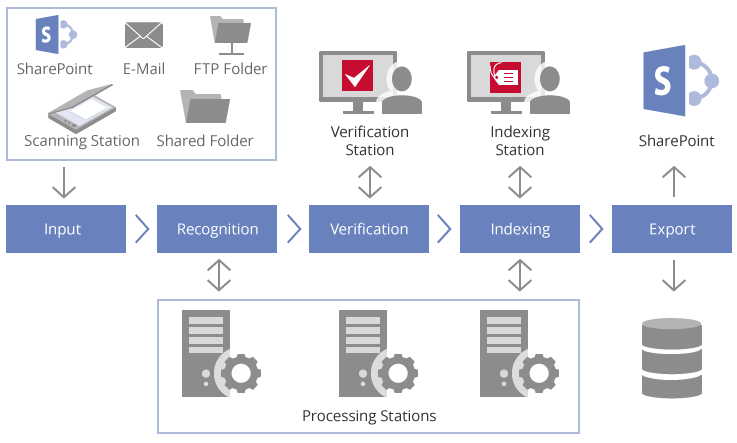
文件處理的六個階段
1. 掃描/導入圖像。 掃描站上的操作員可以掃描圖像,然後將其發送到ABBYY識別服務器,或由ABBYY識別服務器從輸入文件夾(網絡文件夾,FTP文件夾,SharePoint®庫或郵箱)自動導入。 ABBYY Recognition Server將圖像文件排列在隊列中,以根據優先級自動處理它們。
2. 辨認。 OCR過程在處理站上自動運行。 如果系統中安裝了多個處理站,則這些文件將在這些處理站之間均勻分配以實現最佳性能。 部署額外的處理站會使OCR速度呈線性增長。
3. 驗證(可選)。 在某些情況下,例如數字化書籍時,可能需要驗證識別結果。 驗證站允許操作員檢查所有文件或只有低於一定準確度閾值的文件。
4. 文檔分離(可選)。 在執行批量掃描或導入時,可能需要文檔分隔。 可以使用空白分隔頁,條形碼或每個文檔的固定頁數來分隔文檔。 分離也可以根據腳本規則完成。
5. 分類和索引(可選)。 文檔索引可以通過腳本自動完成,也可以由索引站上的操作員完成,這樣操作員可以手動選擇文檔類型並分配文檔屬性。 操作員還可以驗證已由腳本填充的數據。
6. 導出。 在最後階段,ABBYY Recognition Server將輸出文檔發送到目標(可以是網絡文件夾,SharePoint文檔庫或電子郵件地址)。 此外,腳本可以應用於基於文檔類型和屬性的智能路由和文檔交付給ECM系統。
通過優先級管理和調度功能,管理員可以控製文檔的處理順序,並通過在夜間或週末安排OCR來有效使用站點的硬件資源。
功效優點
高性能和高度可擴展的技術可幫助您加快決策流程,為您的客戶提供即時高效的服務,並吸引新的客戶和企業。
阿拉伯語識別
ABBYY識別服務器以99%*的準確度提供快速文檔擷取,包括阿拉伯語在內的190種語言,這在OCR技術中取得了空前的成功。
降低業務流程成本
工作流程和檔案數字化使您降低紙張成本,硬拷貝存儲,手動輸入和處理成本,從而節省資金和工時。
輕鬆設置
ABBYY識別服務器具有直觀的用戶界面,提供快速簡單的設置和實施,包括即用型演示項目,無需培訓,以及快速的技術支持。
投資回報快速
靈活的ABBYY技術授權許可系統,高度的可擴展性和全天候自動化性能使您可以快速獲得投資回報。
ABBYY技術與您現有的環境無縫集成
ABBYY識別服務器具有與微軟的SharePoint集成的固有機制,並且借助開放的API,您還可以順利地將其集成到其他現有的工作流程系統中,而無需額外費用或努力。