文档自动转换解决方案| ABBYY识别服务器

ABBYY识别服务器为文档的自动撷取和PDF转换提供强大的OCR功能的服务器。为分批处理大量文件而设计,它能让公司和扫描服务商通过将纸质文件如TIFF、JEPG和PDF图片文件转换成可全文搜索并长期数码存档的电子文档的格式来建立合算的工作流程。
选择ABBYY Recognition Server的理由

自动转换为PDF和PDF/A格式
能使大型文件包数码化并将扫描文件自动转换为PDF或PDF/A格式以便电子化存储及归档

企业级文档转换服务
为员工和客户提供一个能随时随地在线的灵活的OCR和文件转换服务器

创建可全文本搜索的数据库
将扫描件或者传真件转换为可搜索文本并存储在Microsoft® SharePoint®数据库,以便通过 SharePoint搜索引擎进行搜索
OCR 的授权
产品亮点
用于数字化存档、电子搜索和企业内部访问的自动化文档转换解决方案
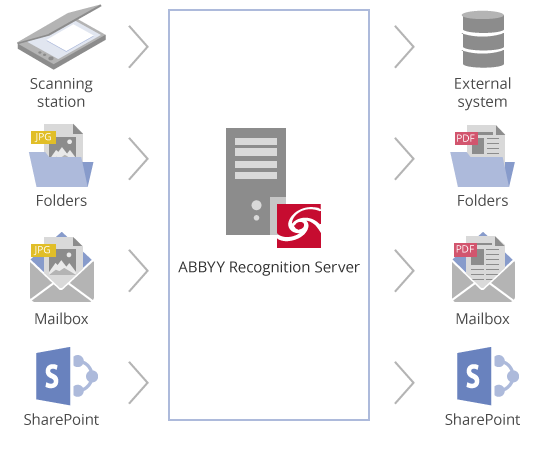
Recognition Server自动从扫描件、文件、传真件、邮件和Microsoft SharePoint数据库中获取图片,执行服务器端的光学字符识别(OCR)并允许添加元数据。将这些结果以需要的格式直接传送到网络文件夹,SharePoint数据库或者其它存储、管理系统。这些格式包括MRC压缩的可搜索PDF或PDF / A文件,XML数据,可编辑文档(如Microsoft Word和Excel®文件)和纯文本文件。
识别服务器的分布式和高度可扩展的架构意味着它可以在网络中的多个服务器上运行,并在短时间内转换大量文档。 其快速部署,易于管理和自动化工作程序使识别服务器成为带来快速回报的投资。
强大的基于服务器的OCR软件,用于自动文档撷取和PDF转换。
产品亮点
自动转换为PDF & PDF/A格式
• 创建全文本可搜索的SharePoint数据库
• 企业级文档转换服务器
自动将文档数字化
如何工作?
1.灵活导入选择
从网络/FTP文件夹导入
ABBYY识别服务器能够从以下网络资源自动导入图片:
- 网络文件夹
- FTP文件夹(例如,从远程位置上传的图片)
- 电子邮件文件夹(例如,用户用电子邮件为客户传的送图片)
文件输入格式
- TIFF/多页TIFF
压缩方式:打开,CCITT Group 3, CCITT Group 3 FAX(2D), CCITT Group4, PackBits, JPEG, ZIP, LZW - JPEG, JPEG 2000
- DjVu
- BMP
- PNG
- PCX, DCX
2. 扫描工作站
扫描工作站提供了批量扫描功能,并做好进一步处理图片的准备:
- 通过TWAIN, WIA and ISIS扫描.
- 快速预览图片
- 图像预处理(旋转、抗扭曲、去处杂点等)
- • 文档条形码、空白页、页码分离。
对于批量扫描的图像,ABBYY Recognition Server提供几个内置文件分离功能:在每个文档的第一页上粘贴或打印的空白页,条形码纸或条形码。基于识别的文本的其他自定义规则可以使用脚本创建。
为了保留原始文档布局,ABBYY Recognition Server使用自适应文档识别技术(ADRT)。将文档保存为DOC和RTF格式时,ADRT可显著提高文档布局保留。复制整个文档的逻辑结构,包括页眉,页脚,脚注,页码,链接到文档部分的目录以及图片和图表的注释。
支持众多识别语言
- 43种主要语言,字典支持: Arabic (Saudi Arabia), Armenian (Eastern), Armenian (Grabar), Armenian (Western), Azeri (Latin), Bashkir, Bulgarian, Catalan, Croatian, Czech, Danish, Dutch, Dutch (Belgian), English, Estonian, Finnish, French, German, German (new spelling), Greek, Hebrew, Hungarian, Indonesian, Italian, Latvian, Lithuanian, Norwegian, Norwegian (Bokmal), Norwegian (Nynorsk), Polish, Portuguese, Portuguese (Brazilian), Romanian, Russian, Slovak, Slovenian, Spanish, Swedish, Tatar, Thai, Turkish, Ukrainian, Vietnamese;
- 没词典支持的133种附加语言: Abkhaz, Adyghe, Afrikaans, Agul, Albanian, Altai, Avar, Aymara, Azerbaijani (Cyrillic), Basque, Belarusian, Bemba, Blackfoot, Breton, Bugotu, Buryat, Cebuano, Chamorro, Chechen, Chukchee, Chuvash, Corsican, Crimean Tatar, Crow, Dargwa, Dungan, Eskimo (Cyrillic), Eskimo (Latin), Even, Evenki, Faroese, Fijian, Frisian, Friulian, Gagauz, Galician , Ganda, German (Luxembourg), Guarani, Hani, Hausa, Hawaiian, Icelandic, Indonesian, Ingush, Irish, Jingpo, Kabardian, Kalmyk, Karachay-balkar, Karakalpak, Kasub, Kawa, Kazakh, Khakass, Khanty, Kikuyu, Kirghiz, Kongo, Koryak, Kpelle, Kumyk, Kurdish, Lak, Latin, Lezgi, Luba, Macedonian, Malagasy, Malay (Malaysian), Malinke, Maltese, Mansi, Maori, Mari, Maya, Miao, Minangkabau, Mohawk, Moldavian, Mongol, Mordvin , Nahuatl, Nenets, Nivkh, Nogay, Nyanja, Ojibway, Ossetian, Papiamento, Provencal, Quechua, Rhaeto-Romanic, Romany, Rundi, Russian (Old Spelling), Rwanda, Sami (Lappish) , Samoan, Scottish Gaelic, Selkup, Serbian (Cyrillic), Serbian (Latin), Shona, Sioux (Dakota), Somali, Sorbian, Sotho, Sunda, Swahili, Swazi, Tabasaran, Tagalog, Tahitian, Tajik, Tok Pisin, Tongan, Tswana, Tun , Turkmen, Tuvinian, Udmurt, Uigur (Cyrillic), Uigur (Latin), Uzbek (Cyrillic), Uzbek (Latin), Welsh, Wolof, Xhosa, Yakut, Yiddish, Zapotec, and Zulu;
- 5种东亚语言: 中文(繁体,简体),日文和韩文;
- 6种语言用于识别18-20世纪印刷的书籍中的旧欧洲文献和哥特式字体:
- 英语
- 法语
- 德语
- 意大利语
- 西班牙语
- 拉脱维亚语
- 4种人造语言: Esperanto, Ido, Interlingua, and Occidental;
- 6种程式语言:Basic, C/C++, COBOL, Fortran, Java, and Pascal;
- 简单的化学公式
- 数字
- 一维条码
- Check Code 39, Check Interleaved 25, Code 128, Code 39, EAN 13, EAN 8, Interleaved 25, CODABAR (without checksum), UCC Code 128, Code 2 of 5 (Industrial, IATA, Matrix), Code 93 , UPC-A, UPC-E, Patch Code and Postnet;
- 二维条码
- PDF 417, Aztec, Data Matrix, QR Code
- 多种文本类型
- Normal, Fax (mode for low-resolution texts), Typewriter, Dot Matrix Printer, OCR-A, OCR-B, MICR (E13B), Gothic
自动质量控制允许管理员为识别准确度设置阈值:文档质量不佳的文档不会被转换,而是存储在单独的文件夹中进行特殊处理。
验证站
用于校对识别结果的客户端工作站。可以为所有页面启用验证,也可以根据准确性阈值进行验证。支持验证权限管理。
索引站
用于文档索引和分类的客户端工作站。
1. 多目标地数据导出
ABBYY识别服务器为数据和图像启用多个目标,并生成可搜索的PDF。
2. 灵活文件输出格式
- PDF, PDF/A-1a, PDF/A-1b, PDF/-2a, PDF/A-2b, PDF/A-2u
- RTF
- DOC, DOCX
- XLS, XLSX
- TXT, CSV
- HTML
- TIFF
- JPEG, JPEG 2000
- JBIG2
- PNG
- EPUB
- XML, Alto XML
- FineReader 内部格式 (FineReader 引擎兼容)
3. 企业系统的可用连接器
- 导出至Microsoft SharePoint
- IFilter用于TIFF文件
- 连接器至Google Search Appliance
4. 可用的定制和集成选项
- 通过XML文件定义的自定义处理参数(XML票据)
- WEB API
- COM API
- 在VBScript和JScript中编写手稿
ABBYY Recognition Server可自动将大量纸质文档或文档图像转换为适合业务流程(包括归档,电子发现和企业搜索)的完全可搜索的电子文本。它使自动化的,无人值守的文件处理 可以从组织内部或远程管理和访问。 Recognition Server还可以连接各种后端系统和第三方应用程序,通过脚本,XML票据,Web服务API或基于COM的API进行集成。 ABBYY智能OCR和PDF转换技术提供高度准确的文档转换,最多可识别190种语言。
架构
ABBYY识别服务器由多个组件组成,可安装在局域网中的一台或多台计算机上。主要组件是:
- 服务器管理器 – 一个中央服务组件,它控制文档处理队列并在工作站之间分配任务。
- 处理站 – 执行识别和文档转换的服务。
- 扫描站 – 用于批量扫描和图像预处理的客户端工作站。
- 索引站 – 用于文件索引和分类的客户端站。
- Google Search Appliance™(GSA)连接器 – 允许Google Search Appliance使用ABBYY Recognition Server从文档图像中提取内容的组件。
- Microsoft®Search Systems(IFilter)连接器 – 允许Microsoft Office SharePoint Server和Windows Search使用ABBYY Recognition Server从文档图像中提取内容的组件。
- 远程管理控制台 – 用于配置和监视识别服务器的客户端控制台。
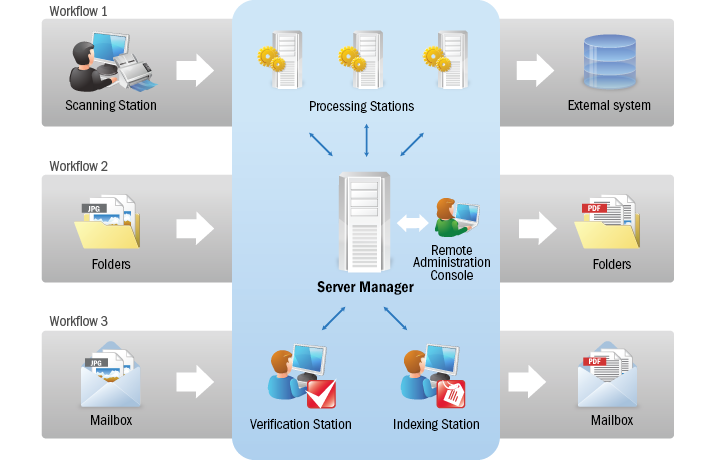
文件处理
ABBYY Recognition Server根据工作流程处理每个图像文件 – 管理员预定义的一组处理参数。 ABBYY识别服务器可以同时运行具有不同参数的多个工作流程。每个工作流程都对应一个唯一的输入源(一个文件夹,一个SharePoint库或一个邮箱)。
处理步骤
ABBYY Recognition Server中的工作流程通常包含多达六个可配置阶段。根据自己的日程安排和优先级,每个工作流独立于其他工作流。
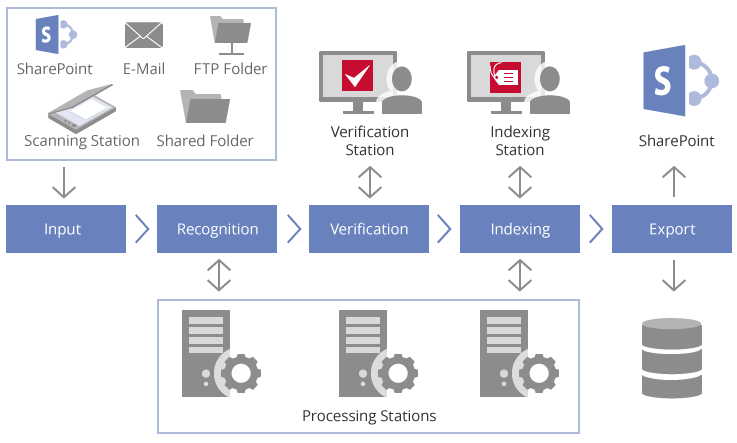
文件处理的六个阶段
1. 扫描/导入图像。 扫描站上的操作员可以扫描图像,然后将其发送到ABBYY识别服务器,或由ABBYY识别服务器从输入文件夹(网络文件夹,FTP文件夹,SharePoint®库或邮箱)自动导入。 ABBYY Recognition Server将图像文件排列在队列中,以根据优先级自动处理它们。
2. 辨认。 OCR过程在处理站上自动运行。如果系统中安装了多个处理站,则这些文件将在这些处理站之间均匀分配以实现最佳性能。部署额外的处理站会使OCR速度呈线性增长。
3. 验证(可选)。 在某些情况下,例如数字化书籍时,可能需要验证识别结果。验证站允许操作员检查所有文件或只有低于一定准确度阈值的文件。
4. 文档分离(可选)。 在执行批量扫描或导入时,可能需要文档分隔。可以使用空白分隔页,条形码或每个文档的固定页数来分隔文档。分离也可以根据脚本规则完成。
5. 分类和索引(可选)。 文档索引可以通过脚本自动完成,也可以由索引站上的操作员完成,这样操作员可以手动选择文档类型并分配文档属性。操作员还可以验证已由脚本填充的数据。
6. 导出。 在最后阶段,ABBYY Recognition Server将输出文档发送到目标(可以是网络文件夹,SharePoint文档库或电子邮件地址)。此外,脚本可以应用于基于文档类型和属性的智能路由和文档交付给ECM系统。
通过优先级管理和调度功能,管理员可以控制文档的处理顺序,并通过在夜间或周末安排OCR来有效使用站点的硬件资源。
功效亮点
高性能和高度可扩展的技术可帮助您加快决策流程,为您的客户提供即时高效的服务,并吸引新的客户和企业。
阿拉伯语识别
ABBYY识别服务器以99%*的准确度提供快速文档撷取,包括阿拉伯语在内的190种语言,这在OCR技术中取得了空前的成功。
降低业务流程成本
工作流程和档案数字化使您降低纸张成本,硬拷贝存储,手动输入和处理成本,从而节省资金和工时。
轻松设置
ABBYY识别服务器具有直观的用户界面,提供快速简单的设置和实施,包括即用型演示项目,无需培训,以及快速的技术支持。
投资回报快速
灵活的ABBYY技术授权许可系统,高度的可扩展性和全天候自动化性能使您可以快速获得投资回报。
ABBYY技术与您现有的环境无缝集成
ABBYY识别服务器具有与微软的SharePoint集成的固有机制,并且借助开放的API,您还可以顺利地将其集成到其他现有的工作流程系统中,而无需额外费用或努力。