数据捕获软件 | ABBYY FlexiCapture

ABBYY FlexiCapture 是非常准确的,可扩展的文档影像和数据提取软件,可以自动转换任何结构,语言或内容的文档转换成可用的和可访问的业务就绪数据。
智能的自学分类和国家的最先进的识别技术使FlexiCapture,以取代自动文档分类和处理容易出错的手动流程。
灵活和可定制的,FlexiCapture可以处理几乎所有的文档处理方案,并可以针对任何公司的工作流程和规定。
为什么选择 ABBYY FlexiCapture?

加速数据输入业务流程的软件
一个系统就可处理所有类型的商业文件

智能自动学习技术,使得设置简单
交互式培训技术简化了系统的实施和建立。

移动文档捕获
FlexiCapture 的手机客户端拍摄提供了文档的替代切入点 – 随时可用,从任何地方。
采集数据,离开纸张。
产品亮点
自动化文档分类
- 任何文档导入到系统后自动分离和分类;
- 分类规则的设置没有限制;
- 随著企业业务的发展而不断扩展的大量数据和文档处理可扩展性。
准确的表格数据提取能力
- 表格行列的自动识别和数据提取
- 通过点击和自动匹配简单设置
- 能跨页提取多页表格或发票的数据
- 能单独提取表格中行数据
- 具有容错性,因扫描的分辨率不同和页面识别问题而造成页面表格的移动
- 能自定义匹配精确提取数据
自动化处理的工作流程
- 自动文档处理,包括导入、分类、识别、提取和导出
- 採用灵活的处理工作流程,可以轻鬆地调整客户的具体业务
- 双重校验:针对关键的业务数据字段,支持两个操作员同时独立校验
与您现有的业务系统集成使用
数据输入
FlexiCapture 支持导入来自:
- 扫描设备 (TWAIN, ISIS, WIA)
- 监控文件夹 (本地或局域网)
- FTP 服务器
- 电子邮件附件(来自MS Exchange服务器和POP3邮件服务器)
支持导入文档格式:
- PDF, BMP, JPEG, JPEG 2000, TIFF, DjVu, PNG, PCX, DCX
数据输出
FlexiCapture 支持输出到:
- 文件夹
- SharePoint 2003/2007/2010/2013
- 通过ODBC输出到数据库
- 任何ERP系统和发票审批工作流
- 任何外部可自定义脚本模块的应用程序
支持输出格式:
数据输出格式: .XML, .TXT, .XLS, .DBF, .CSV.
图像输出格式: PDF (Image only, text under image), PDF/A (Image only, text under image), TIFF, JPEG, JPEG2000, PCX, BMP, PNG, DCX.
处理所有类型文件的一站式解决方案
通过自动数据输入软件加快数据输入业务流程,消除由于人力录入造成的时间和资源浪费。智能的捕获演算法使系统能够处理任何类型的商业文档,包括发票、协议、採购订单、登记表等等。
从任何文档捕获的数据,从结构形式非结构化文本为主的论文。
工作原理?

1. 数据输入选项
- 扫描设备 (TWAIN, ISIS, WIA)
- 监控文件夹(本地或局域网)
- FTP服务器
- 电子邮件附件(来自MS Exchange服务器和POP3邮件服务器)
2. 支持输入文档格式
- PDF, BMP, JPEG, JPEG 2000, TIFF, DjVu, PNG, PCX, DCX
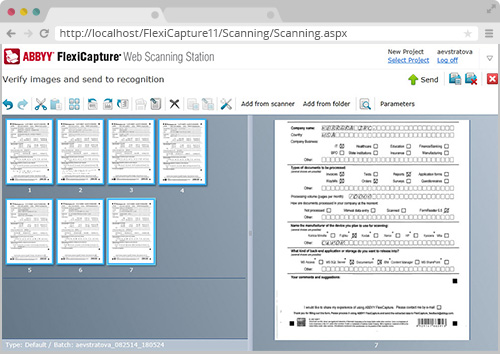
3. 扫描站
FlexiCapture扫描站点可轻鬆通过任何TWAIN-、ISIS-和WIA-功能的设备扫描,可兼容胖客户端方式和瘦客户端方式。
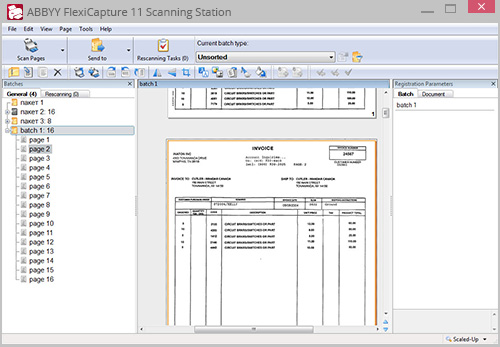
4. 扫描配置文件
扫描站点实现选项扫描,预定义的设置应用程序中的被应用到的特定字段。当扫描新部分的文档,用户只需要从下拉菜单中选择正确的选项。
5. 图像改进
加载或扫描的图像会在处理前得到改善,例如旋转、纠偏、隐藏敏感数据等等。

1. 自动将一个混合页面组合分离为多页文档
由于可以探测文档类型,基于空白页、页码或者ABBYY先进的分类演算法将文档分割成不同类型,从而能加速模板匹配和数据抽取。
2. 自动文档分类
- 内容分类
- 规则分类
- 以上任意组合分类
3. 高精确的 OCR/ICR/OMR 和条码识别技术
- OCR: 支持包括中日韩越南语超过190种语言
- ICR: 支持超过110种语言
- 条码: 支持各种1D和2D条码
- OMR: 支持各种的复选标记

4. 自动验证
- 数据库比较
- 符合内置的验证规则
- 遵循格式
- 数据标准化
- 对其他自定义检查适用
5. 支持多种语言识别
- 包含全内置词典支持的43 种主要语言: 阿拉伯语 (沙乌地阿拉伯),亚美尼亚语 (东部),亚美尼亚 (格拉)、 亚美尼亚 (西部)、 阿泽里语 (拉丁)、 巴什基尔语、 保加利亚语、 加泰罗尼亚语、 克罗地亚、 捷克、 丹麦语,荷兰语,荷兰语 (比利时)、 英语、 爱沙尼亚语、 芬兰语、 法国、 德国、 德国 (新拼写)、 希腊、 希伯来语、 匈牙利、印尼、 义大利、 拉脱维亚、 立陶宛、 挪威、 挪威语 (博克马尔语)、 挪威语 (尼诺斯克语)、 波兰语、 葡萄牙语,葡萄牙语 (巴西)、 罗马尼亚、 俄罗斯、 斯洛伐克、 斯洛文尼亚语、 西班牙语、 瑞典语、 鞑靼、 泰国、 土耳其、 乌克兰、 越南;
- 不含内置词典支持的133 种其他语言: 阿布哈兹、 子音、 南非荷兰文、 安吉尔、 阿尔巴尼亚、 阿勒泰、 阿瓦尔、 艾马拉语、 亚塞拜然语 (西瑞尔文)、 巴斯克、 白俄罗斯文、 贝姆巴、 阿尔衮琴、 不列塔尼、 Bugotu、 布裡亚特、 宿务、 查莫罗、 车臣、 楚克其、 楚瓦什、 科西嘉、 克裡米亚鞑靼文、 乌鸦、 达尔格瓦文、 邓,爱斯基摩人 (西瑞尔文),爱斯基摩语 (拉丁语系),甚至,鄂温克、 法罗语、 斐济、 弗裡斯兰、 弗、 加告兹、 加里斯亚文、 甘达、 德语 (卢森堡)、 瓜拉尼、 哈尼族、 豪萨语、 夏威夷、 冰岛文、 印尼、 印古什、 爱尔兰、 景颇族、 卡巴尔达语、 卡尔梅克、 卡拉恰伊-巴尔卡尔土库曼、 Kasub、 卡瓦、 哈萨克、 中国木偶剧院举行经典、 汉特、 基库尤人,柯尔克孜族、 金刚、 寇里亚克、 克佩莱、 Kumyk、 库尔德、 Lak、 拉丁语、 莱兹吉、 绿霸、 马其顿、 马达加斯加人、 马来文 (马来西亚)、 马林、 马尔他、 曼西、 毛利人、 马里、 玛雅、 庙、 米南卡保人、 莫霍克、 摩尔多瓦、 蒙古、 Mordvin、 纳瓦特尔语、 涅涅茨、 尼、 Nogay、 尼扬贾、 和 Ojibway、 奥塞梯、 阿门、 普罗旺斯、 克丘亚语、 拉托-罗曼尼奇、 吉卜赛、 润、 俄罗斯 (旧拼写)、 卢安达,Sami (拉普兰),萨摩亚语、 苏格兰盖尔文、 Selkup、 塞尔维亚文 (西瑞尔文)、 塞尔维亚文 (拉丁语)、 绍苏 (南达科他州)、 索马里、 索布语、 索托语、 巽他、 史瓦希里文、 农技、 Tabasaran、 他加禄语、 大溪地、 塔吉克、 巴布亚皮钦语、 同安、 茨瓦纳语、 屯、 土库曼、 图、 乌德莫尔特、 维吾尔文 (西瑞尔文)、 维吾尔文 (拉丁语系)、 乌玄别克文 (西瑞尔文)、 乌玄别克文 (拉丁文)、 威尔士、 沃洛夫文、 科萨语、 雅库特、 意第绪语、 萨巴特克和祖鲁语;
- 5种东亚语言: 中文(繁体中文,简体中文)、日语、韩语、朝鲜语(韩国)
- 6种对印製于17-19世纪的古欧洲文献和哥特字体的语言识别:
- 英语,
- 法语,
- 德语,
- 意大利语,
- 西班牙语,
- 拉脱维亚语;
- 4种人造语言: 世界语(Esperanto)、伊多语(Ido)、拉丁国际语/英特林瓜语(Interlingua)和西方语(Occidental);
- 数字
- 1D条码
- Code 39, Check Code 39, Interleaved 25, Check Interleaved 25, EAN 13, EAN 8, Code 128, Codabar, Code 93, IATA 25, UCC-128, UPC-A, UPC-E, Matrix 2 of 5, Industrial 2 of 5, PostNet, Patch code (1, 2, 3, 4, T/Transfer, 6)
- 2D条码
- PDF 417, Aztec, Datamatrix, QR code
- 文本字体
- 印刷、手写、打字机、矩阵打印机、索引、 OCR-A、 OCR-B、 MICR (E13B)、 MICR (CMC7)
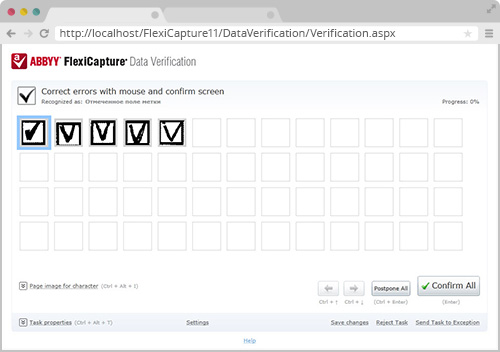
1. 核查小组
复选标记和数字的组验证应用于文档的窗体识别专案中,从整个文档批处理和显示相同的数字(标志) 。
2. 域验证
域验证:逐个检查数据字段。
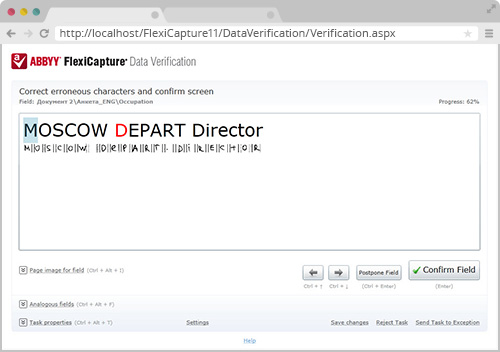
3. 验证文档窗口
验证在文档窗口允许所有必需的数据字段可以同时查看和识别结果与原始图像进行比较。不通过识别的信息,诸如手写文本或注释,可以手动输入到字段中。
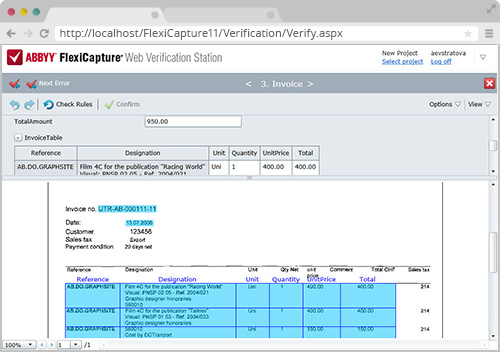
数据验证兼容于胖客户端和瘦客户端版本,并且这个是一个可被跳过的操作阶段。
1. 多目地导出
ABBYY FlexiCapture 能够用于数据、图像以及生成可搜索PDF文档到多个目的地。
2. 灵活的导出选项
FlexiCapture 支持输出到:
- 文件夹
- SharePoint 2003/2007/2010/2013
- 通过ODBC输出到数据库
- 任何ERP系统和发票审批工作流
- 任何外部可自定义脚本模块的应用程序
FlexiCapture 支持输出格式:
数据输出格式: .XML, .TXT, .XLS, .DBF, .CSV。
图像输出格式: PDF (Image only, text under image), PDF/A (Image only, text under image), TIFF, JPEG, JPEG2000, PCX, BMP, PNG, DCX。
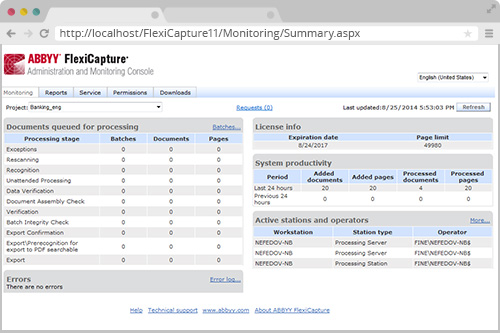
1. 基于Web的管理和监控控制台
AABBYY FlexiCapture 提供了一个基于Web的管理和监控控制台,通过Web浏览器随时随地实现接入监管。管理员可以轻鬆地管理用户权限,检查事件日志,查看标准报告或生成自定义性能报告。
2. 电邮提醒
管理员可以选择接收电子邮件警报一样的错误,许可证过期和页数限制的重要事件。管理员也可以通知有关即将数据库溢出,在运行的磁盘空间不足,请求访问权限,或失败的尝试登录。

- 自定义处理阶段
- 连接到其他的OCR / ICR引擎
- 使用第三方图像增强工具
- 使用自定义的验证客户端
- 连接到签名匹配和其他外部模块
通过使用Web Service API,FlexiCapture可以作为一个自动文档分类和数据捕捉模组能轻松地被集成到不同的商业应用方案和工作流中。